
Concurrent programming is when an algorithm executes several processes at the same time, reducing, in most cases, the time needed to obtain a result. This is done regardless of the amount of CPU the PC on which we deploy the program has.
When developing applications in the cloud, using for example AWS, this type of technique can also be used. However, in the case of lambdas it is possible to make a variation on the traditional method that is normally used. Instead of making a proper multithreaded algorithm, the idea would be to make a lambda that has the concurrent algorithm and run it simultaneously as many times as data you have.
To explain how this would be done, we will do it using the following real case I had in one of the projects I work on. Serverless Framework is used to manage the infrastructure, so the configuration code we will see is based on this framework. Python is used as programming language. Regardless of the technology and language, the important thing is the concepts, hence the main objective of this article.
Case study
One of the applications that I most frequently make are bots for Telegram. A bot basically is a Webhook that would be all the time waiting for new messages from Telegram. Every time a message arrives, it should be processed and responded with one or more messages back to the user in Telegram. Knowing this we can agree that to create a bot it is very feasible to do so using a lambda in AWS.
In any application something that is desirable, is to have information about the use of the system by users. For this, I store metrics in CloudWatch using the aws_embedded_metrics library. Without extending too much, we can ensure that every time the lambda is executed where the bot is implemented, the following information is stored in CloudWatch.

From the JSON above, we are only interested in the fields: is_group and is_new_user and we will make the following queries.
- How many requests have been made from a group. It would be all the requests where the field is_group is equal to true.
- How many requests have been made privately. All the cases where is_group is equal to false.
- How many new users have registered. It would be the cases where the is_new_user field is true.
With these queries we will make a daily report, therefore we will limit the result to 24 hours.
The way that AWS gives us to query the logs and get information is Logs Insights, which with a mechanism similar to SQL we can obtain data of interest, in this case, the metrics. The queries we will make in each case would be.
- filter (is_group=1) | stats count(*) as calls => Number of requests in groups.
- filter (is_group=0) | stats count(*) as calls => Number of private requests.
- filter (is_new_user=1) | stats count(*) as calls => Number of new users.
Two steps are needed to obtain information from the logs. First the query is sent to be executed and then a cycle is made where in each interaction a wait is made and it is checked to see if the result is ready. This is done because CloudWatch does not return the result automatically, but you have to wait some time until it is ready. With this in mind the most logical thing to do would be to create an algorithm that executes the three queries, in this case, in parallel and not have to wait for one to finish so the other can start. Doing it this way we achieve that our logic is scalable.
The application would consist of two lambdas. One that executes a query and returns the result and another one that at the end consolidates all the information and would send it to a recipient, which can be a telegram channel, an email, etc. In this case the first lambda would be the one to be executed concurrently.
Lambda to execute the query
The following code is the lambda that makes the query to CloudWatch to get the data.
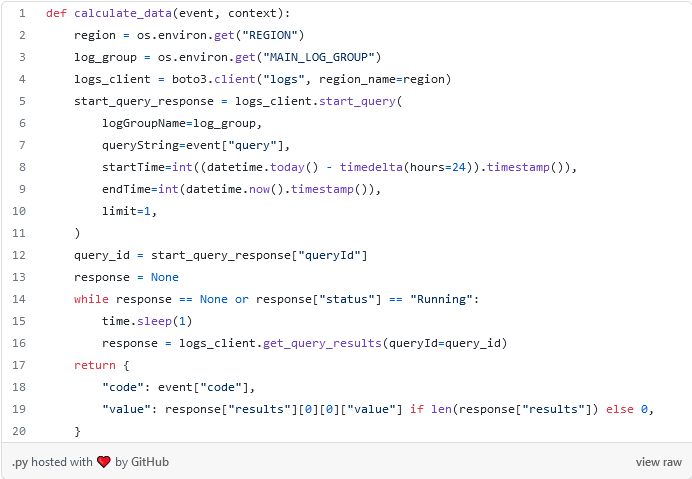
The most interesting is from line 5 to 11, where the query is sent to start. And in line 14 a cycle is made as long as we do not have an answer. Precisely this cycle is what motivates to do this algorithm concurrently. Doing it in a linear way would imply adding this time for each of the queries, something that is not very scalable as the number of queries increases.
Lambda to consolidate the information

This lambda will be executed at the end of the whole process. It basically collects all the information, formats it and then it can be sent to any destination.
Infrastructure configuration.
Up to this point there is nothing special in the code we have developed. It is just two simple functions made with Python. The point is how to tell AWS with which data it should execute each lambda and how to configure that one of them should be executed concurrently.
For this we will use Step Function. This AWS service allows to define a workflow, where in each status can be linked or not a lambda and the output of one status is the input of the next one.
The following is a concrete example, if you want to know more you should go to the documentation. Only the Step function configuration is shown.
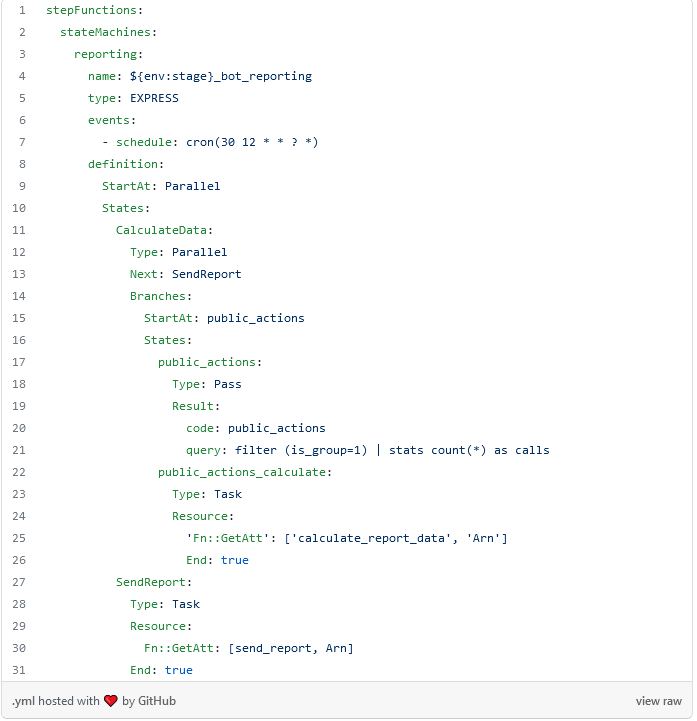
Some interesting notes
Line 5 defines that it is of type EXPRESS, which means that the entire flow will be executed at once, i.e., each time a step is finished, it automatically passes to the next one.
Line 6 defines the event that triggers the execution of the flow. In this case it will be every day at 12:30 UTC.
A flow is formed by statuses where each one has a type and, depending on the type, it works in a certain way. In the example, two statuses are defined. The first one is the one defined in line 11 named CalculateData and the second one in line 27 named SendReport.
The first status is of type Parallel (line 12) which means that internally it will have an array of flows and all of them must be executed concurrently and this is where the magic is. From line 14 to 26 the branches are defined and in the example we only put the case for a query. The idea would be to configure this as many times as you have queries, something that would not be very “pretty” and in the next section we will see how to optimize it.
The SendReport step is executed after all the concurrent flows of the previous step finish and what it receives is an array with the result of each one of the threads.
Improving the configuration with Javascript
In the Step Function configuration file, the configuration of the other queries was removed for clarity. It is necessary to find a way to do the same but in a dynamic way, so that the code is more concise and easier to maintain. For this in Serverless Framework we can generate configuration using javascript and the form would be the following.
First, we will show how the yml will finally look like:
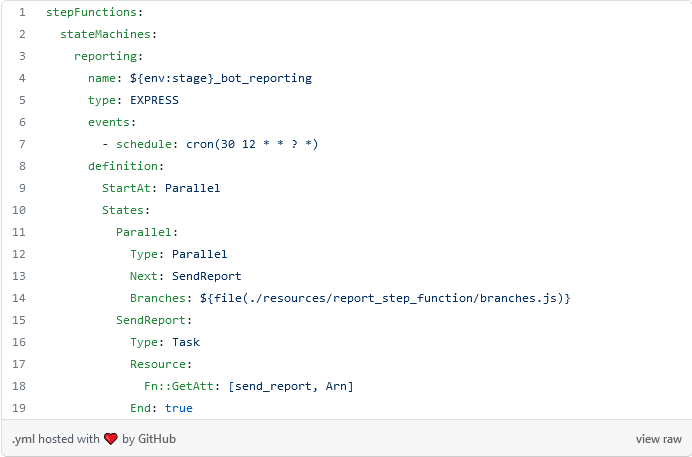
In line 14 we indicate to the framework that we are going to use javascript to generate the configuration dynamically. This way we only need to put the necessary javascript code.
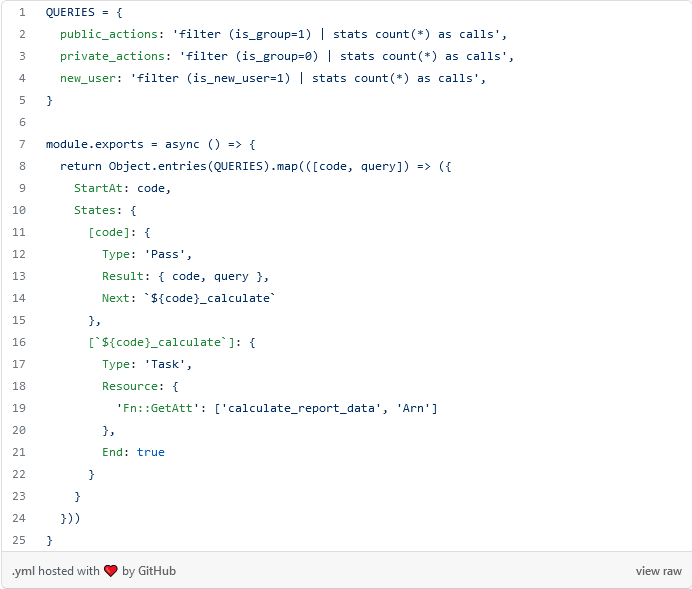
Conclusion
We hope this article can be useful when creating concurrent algorithms in AWS. In this case, rather than creating a traditional multithreaded algorithm, we use the same AWS infrastructure to achieve the same effect. One advantage is that this way of working is completely scalable, you can add more queries (threads) and the effect will be exactly the same. The cost of running one lambda is the same as running 100.
Another lesson is to always analyze what the technology we are using gives us before venturing into development. In this case, implementing concurrency in the traditional way would be a very bad decision and we would not be taking advantage of the potential of cloud computing.