
La programación concurrente es cuando un algoritmo ejecuta varios procesos a la misma vez, reduciendo, en la mayoría de los casos, el tiempo necesario para obtener un resultado. Esto se hace sin importar la cantidad de CPU que tenga la PC en la que desplegamos el programa.
Cuando se desarrollan aplicaciones en la nube, usando por ejemplo AWS, se puede utilizar también este tipo de técnicas. Sin embargo, en el caso de las lambdas se puede hacer una variación en el método tradicional que se utiliza normalmente. En vez de hacer un algoritmo propiamente multihilo, la idea sería hacer una lambda que tenga el algoritmo concurrente y ejecutarla simultáneamente tantas veces como datos se tenga.
Para explicar cómo se haría, lo haremos usando el siguiente caso real que tuve en uno de los proyectos en los que trabajo. Para manejar la infraestructura se utiliza Serverless Framework, por lo tanto el código de configuración que veremos es basado en este framework. Como lenguaje de programación se utiliza Python. Independientemente de la tecnología y el lenguaje, lo importante son los conceptos, de ahí el objetivo principal de este artículo.
Caso de estudio
Una de las aplicaciones que con más frecuencia realizo son bots para Telegram. Un bot básicamente es un Webhook que estaría todo el tiempo esperando por nuevos mensajes desde Telegram. Cada vez que un mensaje llega, se debe procesar y responder con uno o varios mensajes de vuelta al usuario en Telegram. Conociendo esto podemos estar de acuerdo que para crear un bot es muy factible hacerlo usando una lambda en AWS.
En toda aplicación algo que es deseable, es tener información sobre el uso del sistema por parte de los usuarios. Para esto, guardo métricas en CloudWatch usando la librería aws_embedded_metrics. Sin extendernos mucho, podemos asegurar que cada vez que se ejecute la lambda donde está implementado el bot se guarda la siguiente información en CloudWatch.

Del JSON anterior solo nos interesa los campos: is_group y is_new_user y haremos las siguientes consultas.
- Cuantas peticiones se han hecho desde un grupo. Serían todas las peticiones donde el campo is_group es igual a true.
- Cuantas peticiones se han hecho de forma privada. Todos los casos donde is_group es igual a false.
- Cuantos usuarios nuevos se han registrado. Serían los casos donde el campo is_new_user es true.
Con estas consultas haremos un reporte diario, por lo tanto acotaremos el resultado a 24 horas.
La forma que nos brinda AWS para consultar los logs y sacar información es Logs Insights, que con un mecanismo similar a SQL podemos obtener datos de interés, en este caso, las métricas. Las consultas que haremos en cada caso serían.
- filter (is_group=1) | stats count(*) as calls => Cantidad de peticiones en grupos.
- filter (is_group=0) | stats count(*) as calls => Cantidad de peticiones en privado.
- filter (is_new_user=1) | stats count(*) as calls => Cantidad de usuarios nuevos.
Se necesitan dos pasos para obtener información de los logs. Primero se manda a ejecutar la consulta y luego se hace un ciclo donde en cada interacción se hace una espera y se chequea para a ver si el resultado está listo. Esto se hace porque CloudWatch no devuelve el resultado de forma automática, sino que hay que esperar un tiempo hasta que está listo. Teniendo esto en cuenta lo más lógico sería crear un algoritmo que ejecute las tres consultas, en este caso, de forma paralela y no tener que esperar que una termine una para comenzar la otra. Hacerlo así logramos que nuestra lógica sea escalable.
La aplicación estaría formada por dos lambdas. Una que ejecuta una consulta y devuelve el resultado y otra que al finalizar consolida toda la información y lo enviaría a un destinatario, que puede ser un canal de telegram, un correo electrónico, etc. En este caso la primera lambda sería la que se debe ejecutar de forma concurrente.
Lambda para ejecutar la consulta
El siguiente código es la lambda que hace la consulta a CloudWatch para obtener los datos.
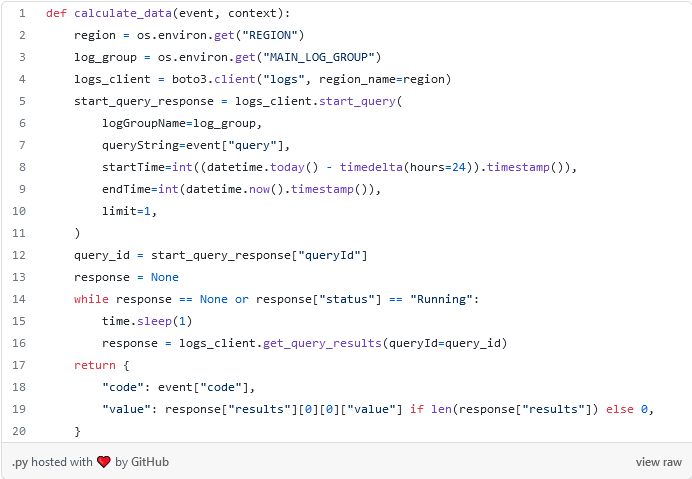
Lo más interesante es de la línea de la 5 a 11, donde se manda a iniciar la consulta. Y en la línea 14 se hace un ciclo mientras no tengamos una respuesta. Precisamente este ciclo es lo que motiva a hacer este algoritmo de forma concurrente. Hacerlo de forma lineal implicaría sumar este tiempo por cada una de las consultas, algo que es poco escalable a medida que aumentan la cantidad de consultas.
Lambda para consolidar la información

Esta lambda se ejecutará al final de todo el proceso. Básicamente recoge toda la información, le da formato y luego se puede enviar a cualquier destino.
Configuración de la infraestructura.
Hasta este punto no hay nada especial en el código que hemos desarrollado. Solamente son dos funciones simples hechas con Python. La cuestión es como indicarle a AWS con qué datos debe ejecutar cada lambda y cómo configurar que una de ellas debe ser ejecutada de forma concurrente.
Para esto utilizaremos Step Function. Este servicio de AWS permite es definir un workflow, donde en cada estado puede estar vinculada o no una lambda y la salida de un estado es la entrada del siguiente.
Lo que se pone a continuación es un ejemplo concreto, si se desea conocer más se debería ir a la documentación. Solamente se pone la configuración de la Step function.
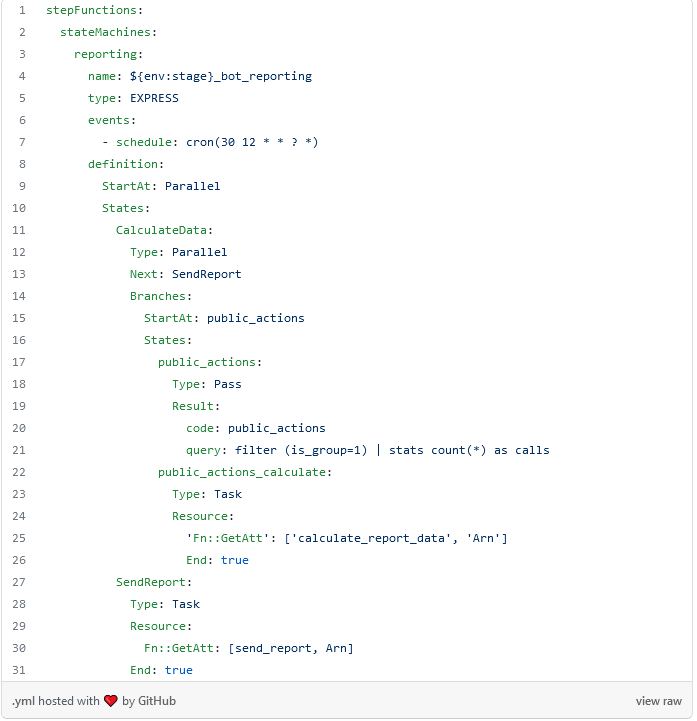
Algunos puntos interesantes.
En la línea 5 se define que es de tipo EXPRESS, lo que significa que todo el flujo se va a ejecutar de una sola vez, es decir, cada vez que termine un paso, pasa automáticamente al siguiente.
En la línea 6 se define que evento desencadena la ejecución del flujo. En este caso será todos los días a las 12:30 UTC.
Un flujo está formado por estados donde cada uno tiene un tipo y en dependencia del tipo funciona de una forma determinada. En el ejempo se define dos estados. El primero es el que se define en la línea 11 que tiene como nombre CalculateData y el segundo en la línea 27 que tiene como nombre SendReport.
El primer estado es de tipo Parallel (línea 12) lo que significa que internamente va a tener un arreglo de flujos y todos deben ser ejecutados de forma concurrente y es aquí donde está la magia. Desde la línea 14 a 26 se define las ramas y en el ejemplo solo se pone el caso para una consulta. La idea sería configurar esto tantas veces como consultas se tengan, algo que no quedaría muy “bonito” y en la siguiente sección veremos como optimizarlo.
El paso SendReport se ejecuta después que todos los flujos concurrentes del paso anterior terminen y lo que recibe es un arreglo con el resultado de cada uno de los hilos.
Mejora de la configuración con Javascript
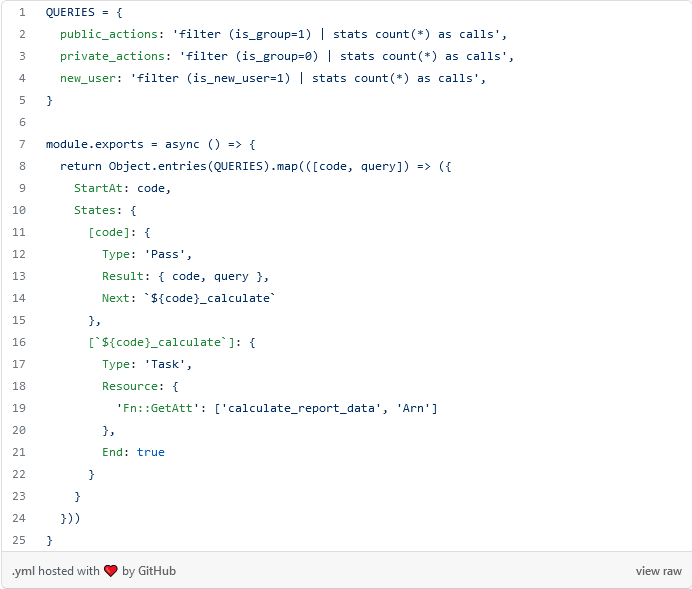
En el fichero de la configuración de la Step Function para lograr mayor claridad se eliminó la configuración de las demás consultas. Se necesita buscar una vía que permita hacer lo mismo pero de una forma dinámica, de forma tal que el código quede más conciso y fácil de mantener. Para esto en Serverless Framework podemos generar configuración usando javascript y la forma sería la siguiente.
Primero podremos como quedaría finalmente el yml:
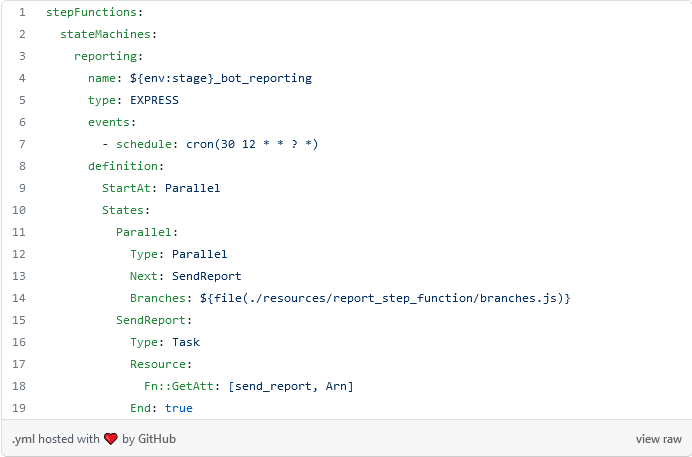
En la línea 14 le indicamos al framework que vamos a utilizar javascript para generar la configuración de forma dinámica. Así solo faltaría poner el código javascript necesario.
Conclusión
Esperamos que este artículo les pueda servir a la hora de crear algoritmos concurrentes en AWS. En este caso más que crear un algoritmo multihilo tradicional, utilizamos la misma infraestructura de AWS para lograr el mismo efecto. Una ventaja, es que esta forma de trabajar, es completamente escalable, se pueden añadir más consultas (hilos) y el efecto será exactamente el mismo. El costo de ejecutar una lambda es el mismo que ejecutar 100.
Otra enseñanza es que siempre analicemos que nos brinda la tecnología que estamos usando antes de aventurarnos a desarrollar. En este caso, implementar la concurrencia de la forma tradicional, sería una muy mala decisión y no estaríamos aprovechando el potencial de la computación en la nube.